AI at Google Cloud Next '18
Last week, from June 24th - 26th, Google held its Google Cloud Next ‘18 conference at the Moscone Center in San Francisco. It was Google’s biggest event ever, with 25000 people attending.
These kinds of specific product-related conferences often end up becoming a sales pitch for the product (justifiable considering the kind of money Google likely put in to host it), so I won’t talk too much about the keynote or the individual talks. There was however an interesting theme across the conference of even greater investment into AI for Google Cloud. This is likely the one major distinguishing factor between Cloud and other similar services like AWS and Azure (which still dominate the market for now). Cloud has managed to grow rapidly as a result, so I thought it’d be worth walking through some of the interesting AI-specific announcements at the conference. Here are some, in no particular order.
Grammar for Google Docs
Docs already has spell check of course, but this is different - the product is supposed to be able to correct complex grammatical errors, like incorrectly used subordinate clauses! I don’t even know what that means, but I assume that means it’s a good grammar checker. Up till now, you could only do that using a dedicated extension like Grammarly, so it’ll be great to have this integrated into docs.
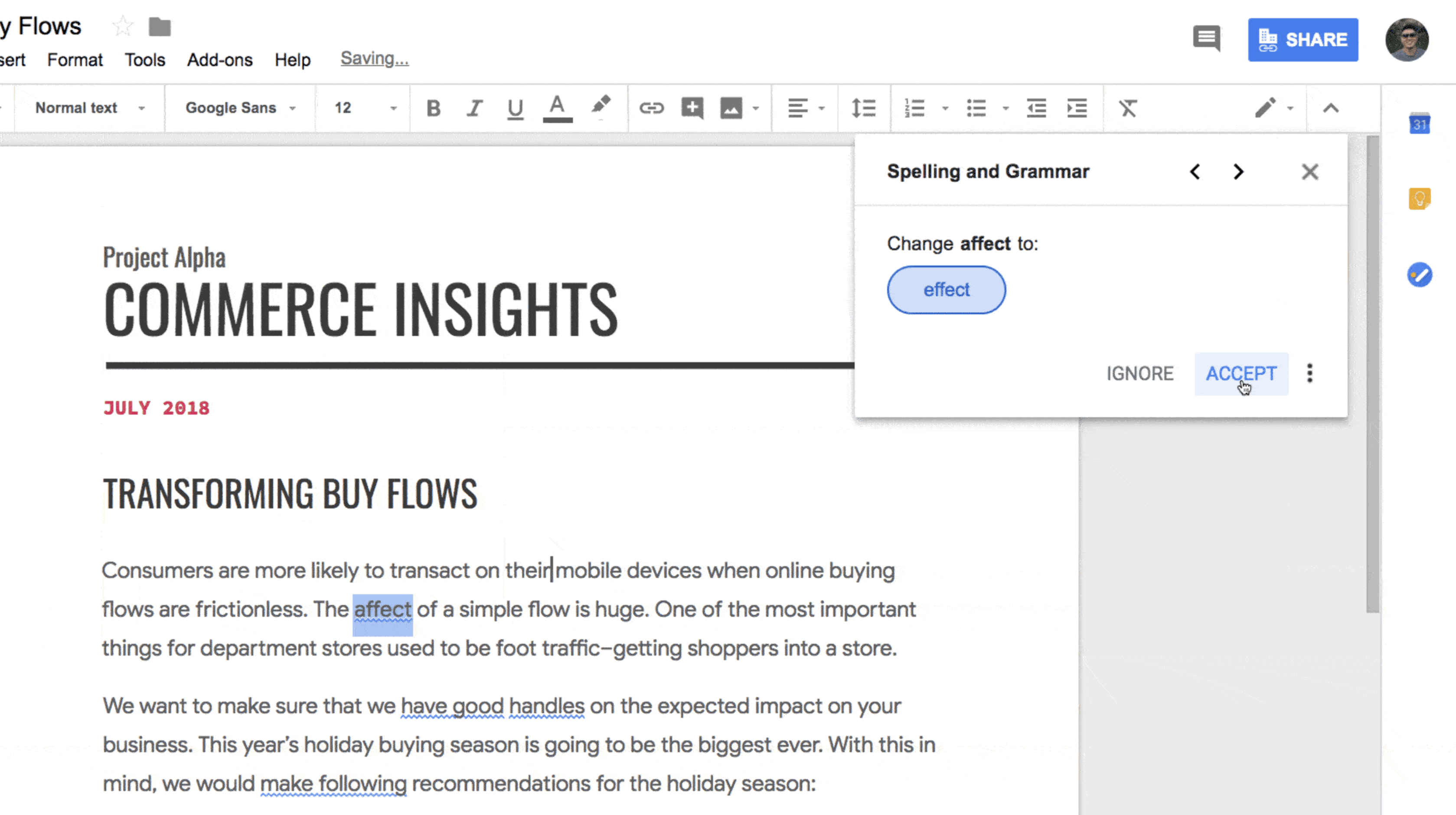
Another interesting part of the announcement is a pointer towards the tech behind this - neural machine translation! That’s the technique used in Google Translate, which means that they’re framing the problem as some sort of translation from a grammatically incorrect language to the grammatically correct equivalent. They also said that the service should get better over time as the system learns from new user data, so a welcome addition all round.
Cloud Vision, Text-To-Speech, Speech-To-Text
Google announced a whole suite of improvements to its existing ML services on Cloud. Cloud Vision now has the option of performing handwriting recognition, and object detection within an image.
Text-to-speech has been beefed up using DeepMind’s Wavenet to add multilingual support and the ability to choose the type of speaker. Speech-to-text is also being improved to identify the language being spoken, function with multiple speakers in the audio, and add word level confidence scores.
Cloud NLP/Translation
A big one - new Cloud NLP and Cloud Translation services! With Cloud NLP, you can upload a big blob of unstructured text and get insights. It already has support for entity recognition, sentiment analysis, syntax parsing, and content category classification. You can train your own translation models with Cloud Translation, but I’m not sure what the use case would be - seems unlikely that you’d ever be able to get enough data to compete with Google Translate. Either way, the Translation service does include an API to access Google Translate which is definitely a useful addition.
AutoML
One of the most unique aspects of Cloud’s ML capabilities, and the one factor that is most likely to help bridge the gap to AWS and Azure, is AutoML. That’s the name of Google’s automated neural architecture search process. Finding the right architecture for a neural network is an important meta problem in deep learning that is more of an art than a science - it requires extensive experimentation and tuning from a human engineer, and it is difficult to automate.
AutoML on Google Cloud does the architecture search for you. All you have to do (with Cloud Vision for example) is upload the labelled data. AutoML will handle everything else - it’ll find the right architecture, tune your hyperparameters, train and evaluate. This allows devs with limited ML experience to train state-of-the-art models for their task with ease.
Google has published a couple of papers recently about how AutoML works, summarized well this blog post. The key idea is to use evolutionary algorithms. These mimic the evolutionary process by starting with a set of potential solutions, introducing mutations in every iteration (or generation) and only keeping the fittest solutions around for the next generation, letting the other ones “die out”.
In the context of architecture search, the potential solutions are different neural network architectures, the mutations are modifications to the architecture (adding or removing an element, tuning a hyperparameter), and the fitness criterion is training accuracy. It would be possible to “rig” the process for success by introducing complex mutations that incorporate human knowledge - an extreme example would be a mutation that just changes the whole architecture to any of the most popular state-of-the-art architectures currently known, such as InceptionNet or ResNet. In the first of Google’s two papers on the topic, they address this by using very simple starting architectures and mutations, and still managing to achieve good results. This means that it is the evolutionary process and not human knowledge that is doing most of the work.
Following this, they published another paper that does use human knowledge more extensively in the starting conditions and in the mutations, and this combination of evolutionary search augmented with human knowledge achieves state-of-the-art results on some popular datasets. One key advantage of evolutionary architecture search over other methods (random search, reinforcement learning) is that the amount of computational power needed to achieve good results is significantly lower, meaning that in theory, you wouldn’t need the level of resources Google has to run it successfully.
Voice for Meet Hardware
The Google Meet hardware is meant to make tele-conferencing even more convenient - I can vouch for it personally since Twitter uses the Meet hardware, and it really does make remote collaboration as fluid and smooth as it can get (well at least without VR, but we’re still a few years away from that). This update essentially adds some of the Google Assistant magic to the Meet hardware. The hardware is pretty easy to use as is, but a lot of meetings do start with a bit of fumbling around to find the remote and dial into the right meeting, so being able to say “Hey Google, start the meeting!” is something I’m looking forward to.
KubeFlow
If AI for Cloud was one big theme of the conference, the other big one was, undoubtedly, containerization. Kubernetes is rapidly gaining in popularity and now has a large community of open source developers working with it. There were some Interesting announcements surrounding Kubernetes like GKE On-Prem (allowing you to use the Google Kubernetes Engine with your local clusters) and Istio (meant to ease the administrative work of containerization from what I understand).
The one place where the AI and the containerization themes meet is KubeFlow - Kubernetes + Tensorflow. KubeFlow is meant for easily deploying ML workflows with Kubernetes. It makes it easy to develop ML training pipelines, and move it across different environments, like going from prototyping on your local machine to testing on a development cluster to actually serving on a production cluster. Anywhere you use Kubernetes, you should be able to use KubeFlow. The announced KubeFlow v0.2 has an improved UI and better monitoring and reporting tools.
Smart Reply
We’ve seen smart reply in Gmail for while. It’s that set of 3 short responses that you can choose from for emails - Sometimes a little brusque, but it can be useful for quick replies. Google is now bringing a similar feature to Hangouts chat. The aim is to provide the right balance between casual replies but in a professional setting, and I think that the shortness of smart reply is much better suited for chat than email. Additionally, the feature is supposed to learn your “voice” better over time, to make your replies more authentic.
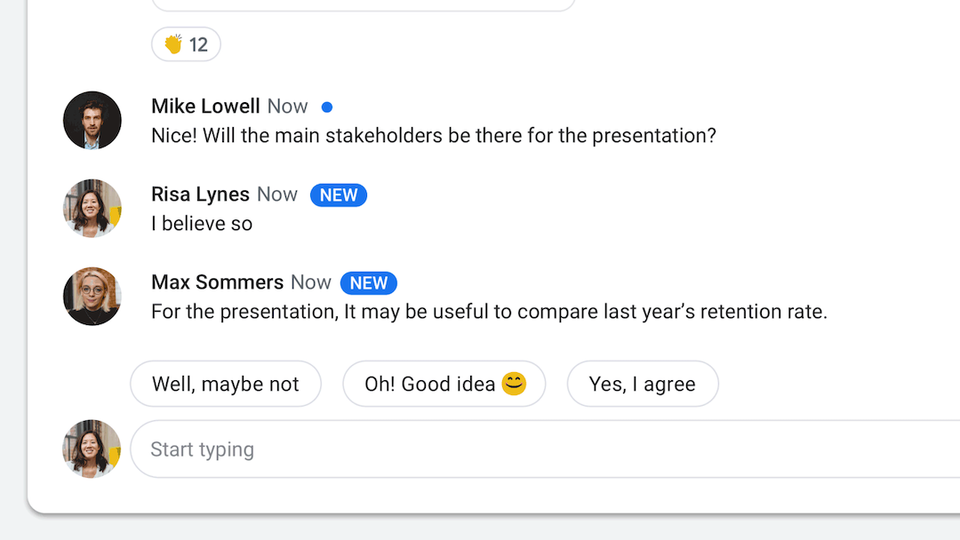
Smart Compose
Smart compose is essentially a beefed up version of the current smart reply that’s available for email. The feature helps to autocomplete your sentences as you type them, and also learns your usual greetings and common information (like address) over time, so that there’s less need for repetition and mundane text. This could potentially be a big productivity boost if the feature works as well the demo seems to suggest.
This is one of the few features for which there’s a pretty detailed technical explanation available. As the suggestions are supposed to show up as you type, there are very strict constraints on the latency (< 100 ms). Additionally, researchers cannot access the data directly as it involves private emails. The task is also not one of typical language generation, as there is a significant dependence on the email subject, and any previous email body if you’re typing out a reply.
The first attempt was a sequence to sequence model, using the previous body and email subject as input along with the text typed until now, and while it worked well, it didn’t come close to satisfying the latency constraint.
The approach that they ended up taking was Bag of Words combined with a word-level RNN language model. An embedding was obtained for the previous body and the subject as an average of word level embeddings, and this was used along with the current word in the email to generate predictions for the next word. This turned out to be much faster, with only a slight sacrifice to the model quality. Additionally, switching to TPU’s instead of CPU’s ended up making inference even faster, bringing the latency down to 10’s of milliseconds.
Scikit-learn and XGBoost in Cloud ML Engine
Earlier, to get online predictions from Cloud ML engine, you could only use trained Tensorflow models. Now, the ML engine can be used with sklearn or XGBoost models trained elsewhere (say, on your local cluster) in a similar way.
Dialogflow improvements
Dialogflow is a Google product used to build interactive text and voice agents. A chatbot builder essentially (Not really related to Google Duplex). It’s meant to help developers build interactive agents without a deep understanding of AI and NLP.
Dialogflow has seen some significant improvements. You can now upload raw unstructured text data (like FAQs) and use “Knowledge Connectors” to extract relevant information for the agent from them. It uses sentiment analysis to know whether to hand the reins over to a human agent for instance. Text conversations now automatically account for spelling corrections similar to Google search, and the Text-To-Speech part of the voice agent now uses WaveNet.
Contact center AI
These Dialogflow improvements have enabled Google to enter another interesting domain - Contact Center AI. This essentially includes a suite of products that are meant to enhance your customer support experience.
The first includes actual virtual agents. Instead of relatively rigid flowcharts of dialogue, this gives you the option of providing open ended conversation over text or phone to customers. The requisite speech recognition, NLP and speech synthesis are all handled and stitched together for ease of use.
The second product is contextual routing. When needed, the virtual agent routes the call to an appropriate human agent at a call center. Depending on information available about the human agents and the existing conversation information from the virtual agent, some smart matching can be done to route to the agent best capable of handling the specific query.
The third is Agent Assist. This is meant to help human agents while they handle queries by providing a live transcription of the conversation using Text-To-Speech, and suggesting relevant articles in real time for the agent to reference.
Additionally, there’s a Conversational Topic Modeler that uncovers insights from past audio conversations. These insights could potentially be used to help develop a better virtual agent, find important topics for agent training or areas of improvement for the knowledge base.
BigQuery ML
I thought this one was particularly cool. BigQuery ML Allows you to train ML models using - wait for it - simple SQL queries! The aim is to democratize AI by allowing data analysts and SQL practitioners to use ML without having to dive into an entirely new framework (like TensorFlow). As an added bonus, there’s no need to export or reformat the data to fit the modeling framework you’re using. You’re basically bringing the ML to the data warehouse itself.
TPUs
The Tensor Processing Unit is a custom chip designed by Google to speed up machine learning computations. It’s an Application Specific Integrated Circuit (ASIC), meaning that it’s built to be used for this one purpose. It’s designed keeping two key ideas regarding ML computations in mind - you don’t usually lose much by lowering the precision of your calculations, and most steps in ML training and inference can be expressed as matrix multiplications. The resulting TPU is a powerful device that drives a lot of Google’s production and development systems.

The TPU v2 (180 teraflops, 64 GB High Bandwidth Memory) is now available for anyone to use through Google Cloud. The TPU v3 which is significantly more powerful (420 teraflops, 128 GB HBM, watercooled) is now available in alpha. For context, one of the most popular GPU’s available on the market (and commonly used for ML training), the Titan X, is roughly 10 teraflops and has 12 GB memory. Additionally, TPU v2 Pods are now available which are essentially networks of TPU v2 units. They boast an insane 11.5 petaflops and 4TB HBM, just in case you wanted to reproduce DeepMind’s AlphaGo results at home.
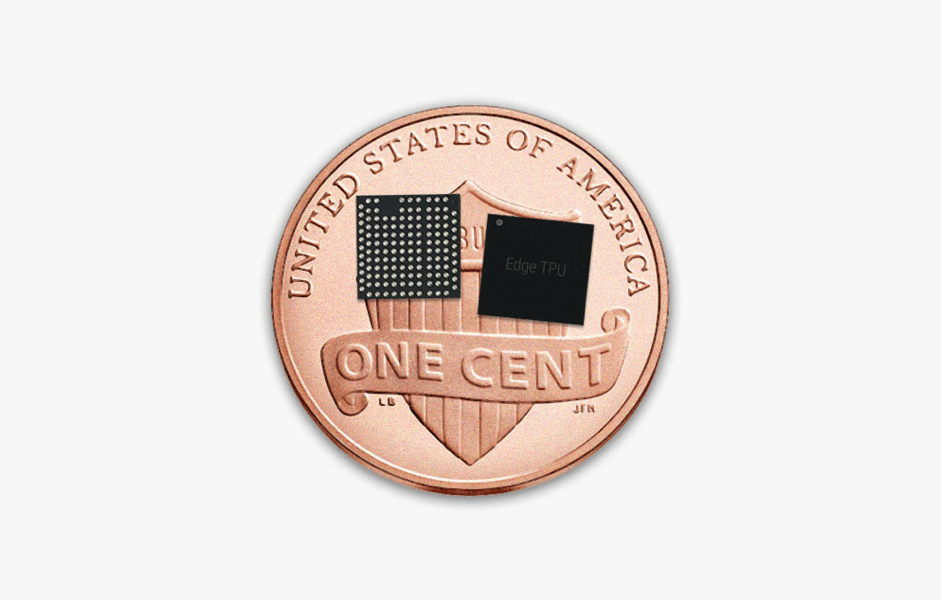
An even more exciting announcement, I believe, is the Edge TPU. It’s a tiny TPU (smaller than a penny) that’s designed to be able to run TensorFlow Lite for ML inference. So you train your models on huge powerful clusters (a TPUv2 Pod for instance) and then you deploy it to your IoT device or your phone without having to worry about excessive computational requirements. I look forward to see some exciting applications of the Edge TPU soon.
You can read more about other announcements from the conference in these two posts. Cloud Next has certainly made it clear that GCP is going to be a strong competitor to AWS and Azure over the next few years. Additionally, each of their AI announcements is likely to put some competitor out of business in that particular field. Grammar for Google Docs threatens Grammarly. Contact Center AI challenges IBM Watson and startups like Cogito and Smart Action. Dialogflow is meant to compete with pretty much every chatbot startup out there. AutoML at its best would probably make companies like SigOpt obsolete.
Google wants to absolutely dominate every AI related field, and the announcements from Cloud Next and earlier this year at Google I/O show strong steps in that direction.